








取消し
カスタマイズ
DesignCapを選ぶ理由

豊富なテンプレート
さまざまなイベントのために専門家によって設計された数千のカスタマイズ可能なロゴテンプレートは、無限のインスピレーションを提供します。

豊富な要素
100以上のスタイリッシュなフォント、220,000のクリップアートが、アイデアを実現するためのショートカットを提供します。

強力な編集ツール
DesignCapのロゴメーカーツールを使用すると、ロゴにテキスト、図形、背景、または写真を追加するなど、数回クリックするだけで編集を行うことができます。

掘り出し物
DesignCapは、ロゴを作成するための無料のリソースを常に提供します。予算の心配はありません。
ロゴを3ステップで作成する方法
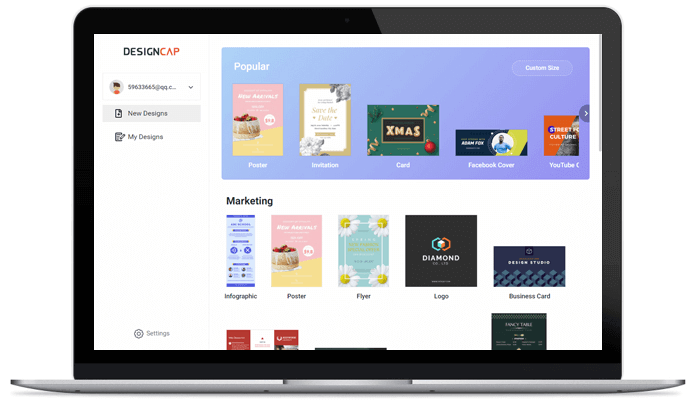
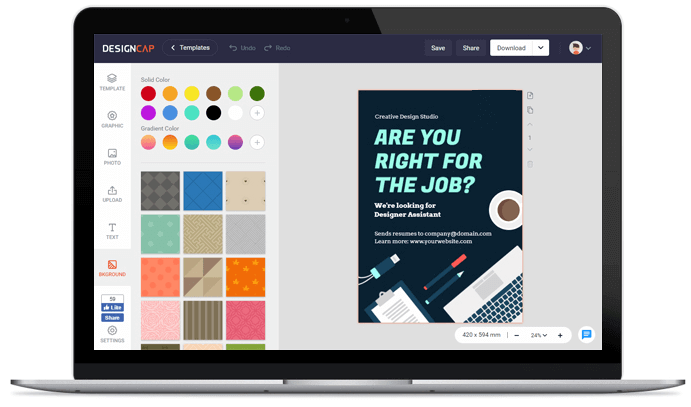

1. テンプレートの選択
ロゴテンプレートから選択して、デザインを開始。
2. カスタマイズ
シンプルでありながら強力な編集ツールでロゴをカスタマイズ。
3. エクスポート
ロゴをコンピューターに保存するか、オンラインで共有。
ユーザーの評価

ポスターが簡単に作成出来るポスターメーカー。何が良いって、 時間やお金、HDDのスペースを節約出来る。

といったイベントなどの広告素材を作りたいけど、プロのデザイナーにお願いする費用が無い……という場合や、スピード優先で自分でデザインしたい! といった方に最適なwebサービスです。
テンプレートを利用すれば、広告、販売、結婚式、イベント、ホリデーなどのあらゆる目的のポスターを簡単に作成することができます。