








取消し
カスタマイズ
DesignCap機能のハイライト

高品質のテンプレート
専門家によって作成のfacebook投稿テンプレートは、無限のアイデアを提供します。すべてカスタマイズ可能です。

豊富な要素
何千ものプロがデザインしたフォント、シェイプ、アイコンがあなたのアイデアを実現します。

使いやす
さfacebook投稿の編集は、素人でも数回クリックするだけで行えます。

掘り出し物
予算を心配しないでください。DesignCapは常に無料のリソースを提供します。
Facebook 投稿を3ステップで作成する方法
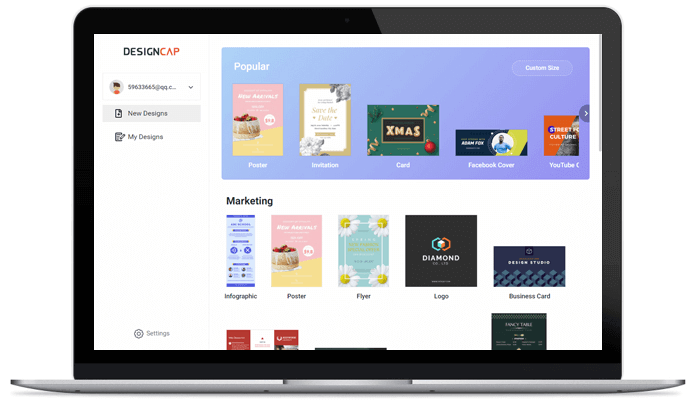
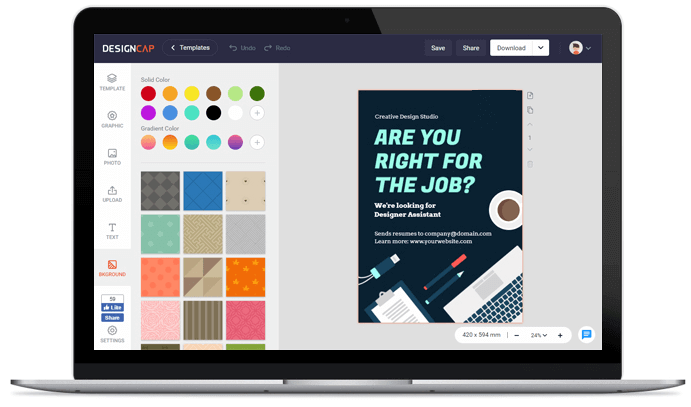

1. テンプレートの選択
Facebook 投稿テンプレートから選択して、デザインを開始。
2. カスタマイズ
シンプルでありながら強力な編集ツールでFacebook 投稿をカスタマイズ。
3. エクスポート
Facebook 投稿をコンピューターに保存するか、オンラインで共有。
ユーザーの評価

ポスターが簡単に作成出来るポスターメーカー。何が良いって、 時間やお金、HDDのスペースを節約出来る。

といったイベントなどの広告素材を作りたいけど、プロのデザイナーにお願いする費用が無い……という場合や、スピード優先で自分でデザインしたい! といった方に最適なwebサービスです。
テンプレートを利用すれば、広告、販売、結婚式、イベント、ホリデーなどのあらゆる目的のポスターを簡単に作成することができます。